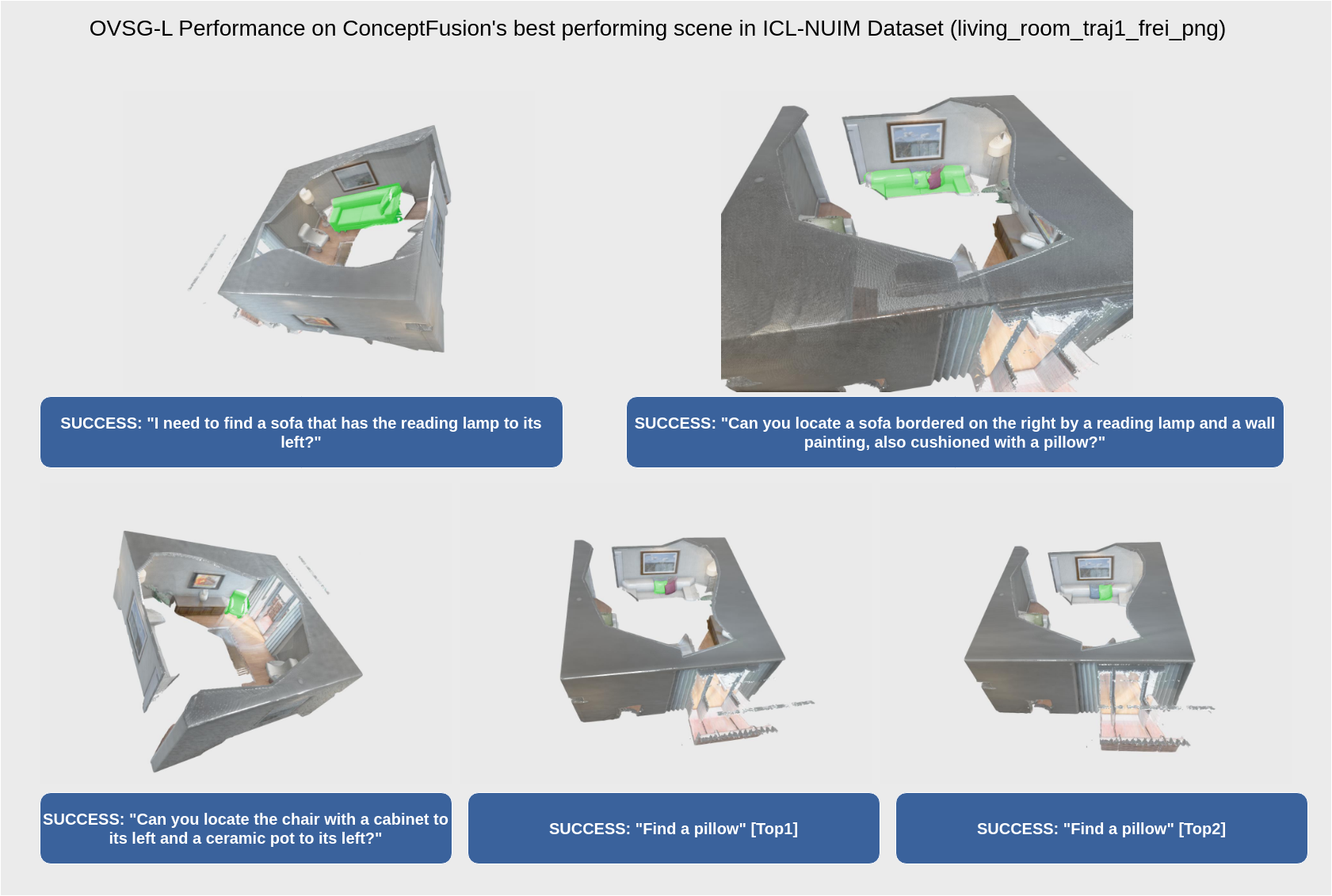
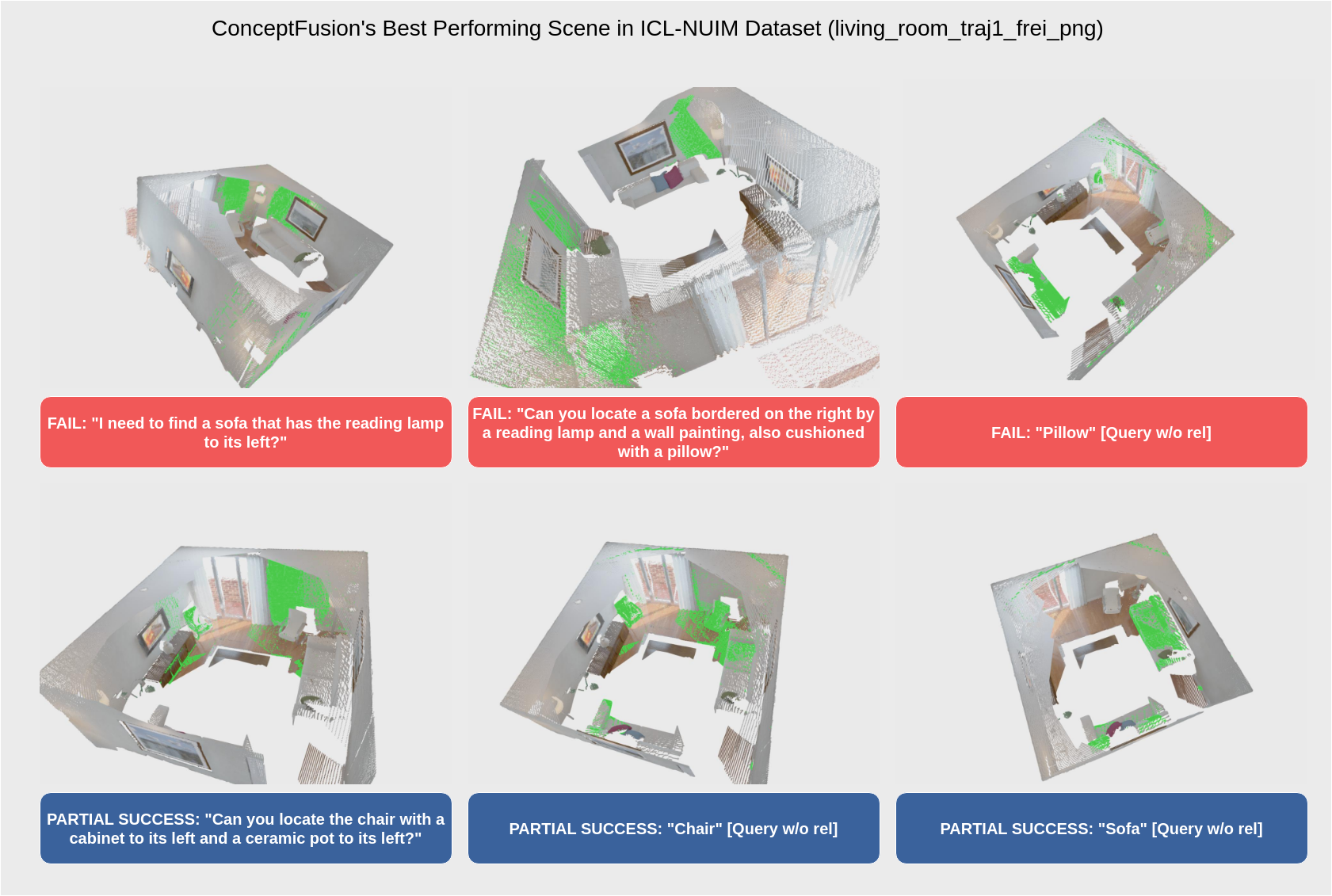
Open Vocabulary 𝟑d Scene Graph (OVSG)
Backbone of our system: OVIR-3D

At the core of our system lies Open-Vocabulary 3D Instance Retrieval(OVIR-3D).
Given a 3D scan reconstructed from an RGB-D video and a text query, the proposed method retrieves relevant 3D instances (see examples a-c).
Notably, instances that aren't even part of the original annotations can be detected (see examples d-e), such as the cushions on the sofa.
Our Pipeline
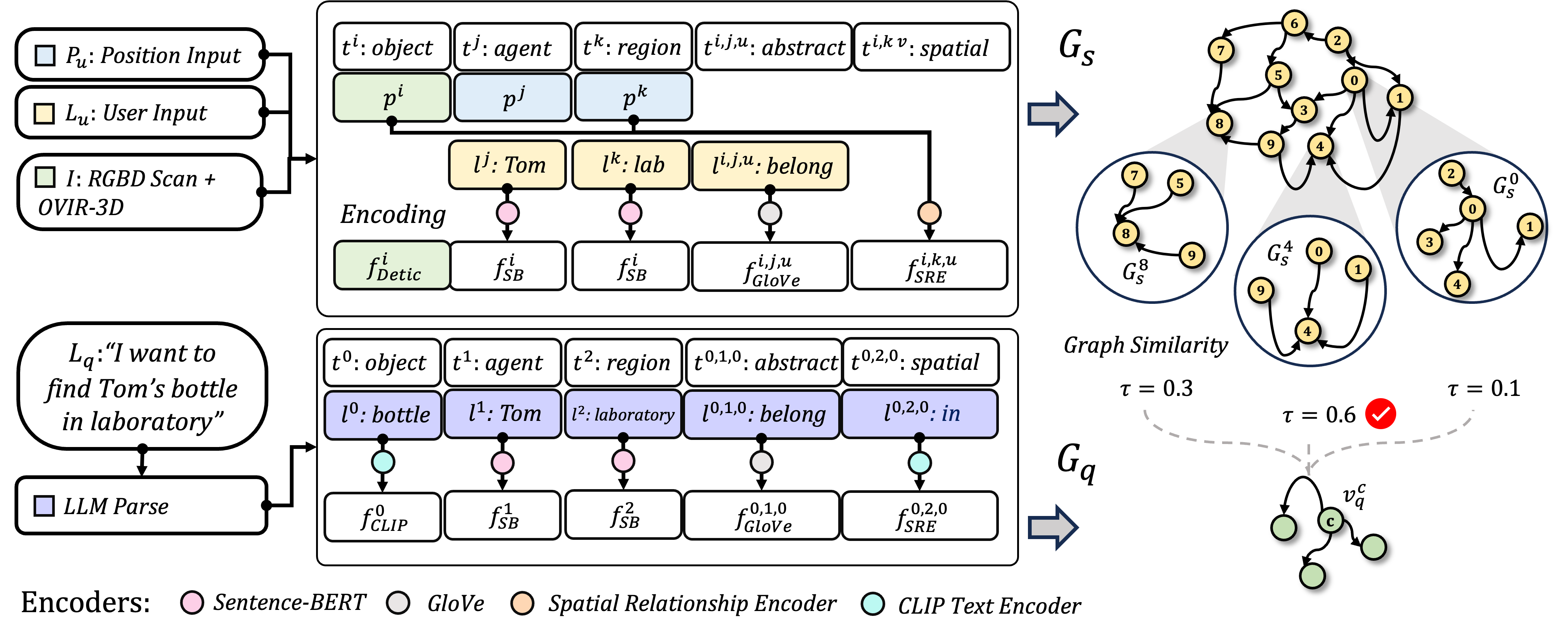
Our proposed pipeline operates on inputs like positional
Pu, user Lu,
RGBD Scan I.
The top section demonstrates the creation of Gs , with Pu and Lu directly channeled into it, while the RGBD Scan I merges with the OVIR-3D system,
leading to position and Detic feature outputs for each item.
The language descriptions undergo encoding processes, including a special Spatial Relationship Encoder for poses.
The bottom section delves into the formation of Gq, derived from the example query
I want to find Tom's bottle in the laboratory.
An LLM breaks down the query into elements which are then feature-encoded to create Gq .
The challenge is matching Gq within Gs, using a new proposal and ranking algorithm, where the desired entity is the central node
of the top-ranked candidate.
At the core of our system lies Open-Vocabulary 3D Instance Retrieval(OVIR-3D). Given a 3D scan reconstructed from an RGB-D video and a text query, the proposed method retrieves relevant 3D instances (see examples a-c). Notably, instances that aren't even part of the original annotations can be detected (see examples d-e), such as the cushions on the sofa.
Our proposed pipeline operates on inputs like positional Pu, user Lu, RGBD Scan I.
The top section demonstrates the creation of Gs , with Pu and Lu directly channeled into it, while the RGBD Scan I merges with the OVIR-3D system, leading to position and Detic feature outputs for each item. The language descriptions undergo encoding processes, including a special Spatial Relationship Encoder for poses.
The bottom section delves into the formation of Gq, derived from the example query I want to find Tom's bottle in the laboratory. An LLM breaks down the query into elements which are then feature-encoded to create Gq .
The challenge is matching Gq within Gs, using a new proposal and ranking algorithm, where the desired entity is the central node of the top-ranked candidate.